How to search multiple PDF documents for words on Linux
Last updated on November 18, 2020 by Dan Nanni
When it comes to searching text within a PDF document, pretty much every PDF reader supports it. However, it becomes tricky when there are more than one PDF document to search. While the official Adobe Reader offers multiple PDF search functionality (i.e., searching all PDF files in a directory), it has discontinued on Linux. None of other third-party PDF viewers (e.g., Evince, Okular, Xpdf) can search multiple PDF documents.
There are command-line tools like pdftotext or pdfgrep that can be used to do simple search on multiple PDF documents at once. In this tutorial, I am going to introduce a desktop application called Recoll, which is much more advanced and user-friendly than these command-line utilities.
Let's find out how to search multiple PDF documents for text by using Recoll.
What is Recoll?
Recoll is an open-source desktop application specializing in text search. For fast, repeated search, it maintains a pre-built database index for all document files in a target storage location (e.g., a specific folder, home directory, disk drive, etc). The document index contains texts extracted from document files by external helper programs. Using the document index, Recoll can perform more advanced queries than simple regular expression based search.
The powerful features of Recoll include:
- Supports multiple document formats (e.g., PDF, Doc, Text, HTML, mailbox).
- Automatically indexes document contents from files, emails, email attachments, compressed archives, etc.
- Indexes web pages you visited (with the help of Firefox extension).
- Supports multiple languages and Unicode-based multi-character sets.
- Supports advanced search, such as proximity search and filtering based on file type, file system location, modification time, and file size.
- Supports search with multiple entry fields such as document title, keyword, author, etc.
Install Recoll on Linux
To install Recoll and external helper programs on Ubuntu, Debian, or Linux Mint:
$ sudo apt-get install recoll poppler-utils antiword
To install Recoll and external helper programs on Fedora:
$ sudo yum install recoll poppler-utils antiword
To install Recoll on CentOS or RHEL, first enable EPEL repository, and then run:
$ sudo yum install recoll poppler-utils antiword
Build a Document Index with Recoll
To launch Recoll, simply run recoll command:
$ recoll
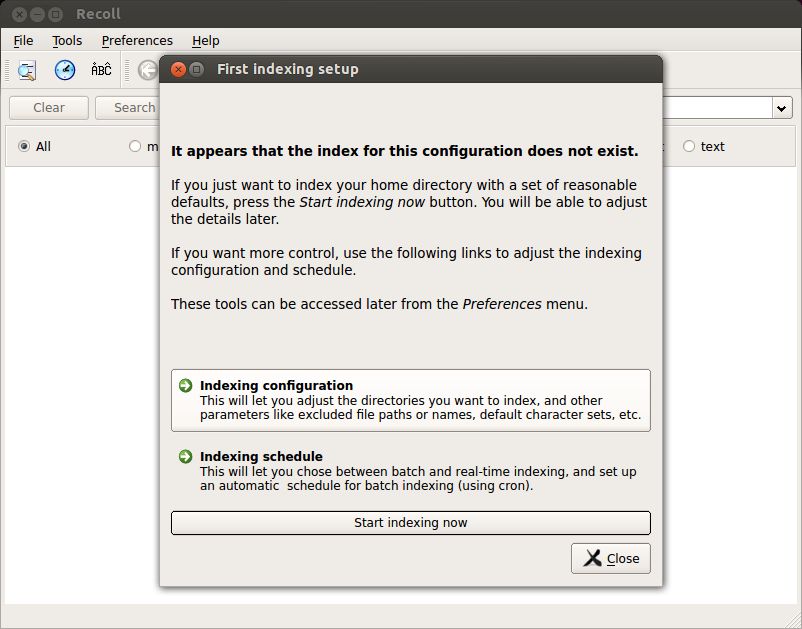
The first time you launch Recoll, you will see the screen shown below. You will be asked to choose one of two menu before starting indexing: (1) Indexing configuration which controls how to build a document database index, or (2) Indexing schedule which controls how often to update a database index. For now, click on Indexing configuration menu.
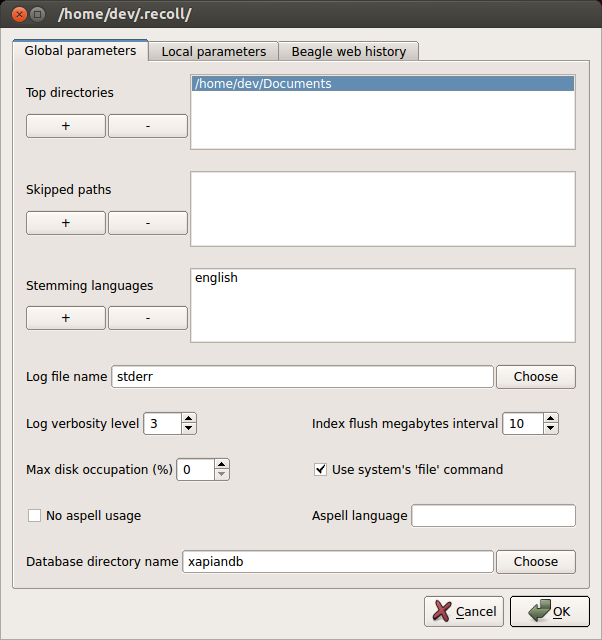
In the configuration window, you will see Top directories (directories which contain documents to search), and Skipped paths (file system paths to avoid when building a document index) under General parameters tab. In this example, I add ~/Documents to Top directories field.
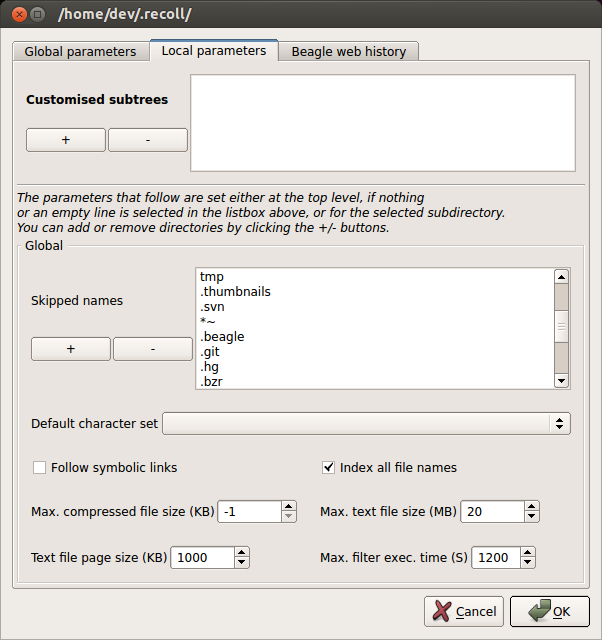
Under Local parameters tab, you can specify other indexing criteria, such as file names to skip, max file size, etc. Once you are done, go ahead and create a document database index. The document index building process uses external programs (e.g., pdftotext for PDF documents, antiword for MS Word documents) to extract texts from individual documents, and create an index out of the extracted texts.
Once an initial document index is built, you can check what kind of documents have been indexed, by going to Help-->Show indexed types menu. Make sure that application/pdf mime-type is included.
Search Multiple PDF Documents for Text
You are now ready to conduct document search. Enter any word or phrase (with quotes) to search for.

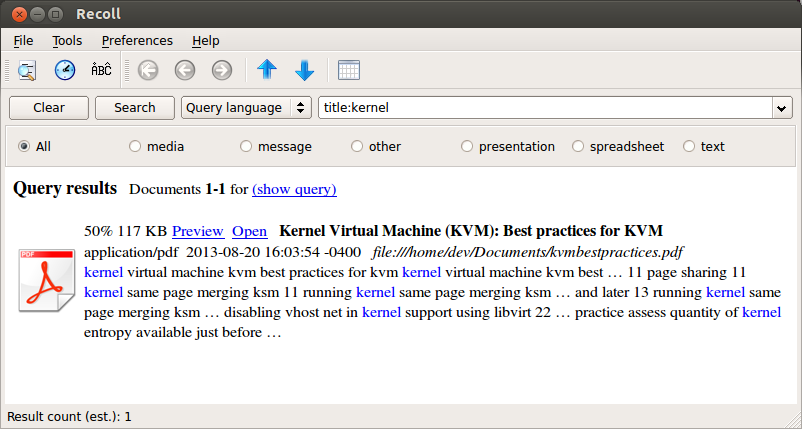
A search result shows a list of PDF documents sorted by their matching scores. The search result includes document snippets and page number information that are matched with search query. You can check document previews, or open the matched documents by using an external PDF viewer.

Using Recoll, you can search PDF documents that contains specific word(s) in the document title. For example, by typing in title:kernel in search query, you can search for PDF documents which contain kernel in their titles.
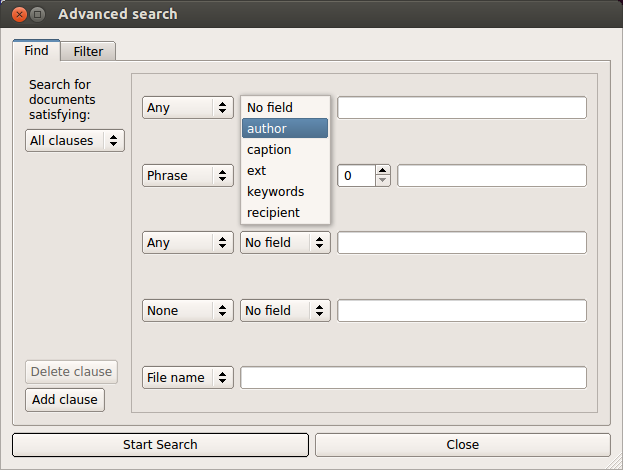
Using advanced search option, you can define various other search criteria.
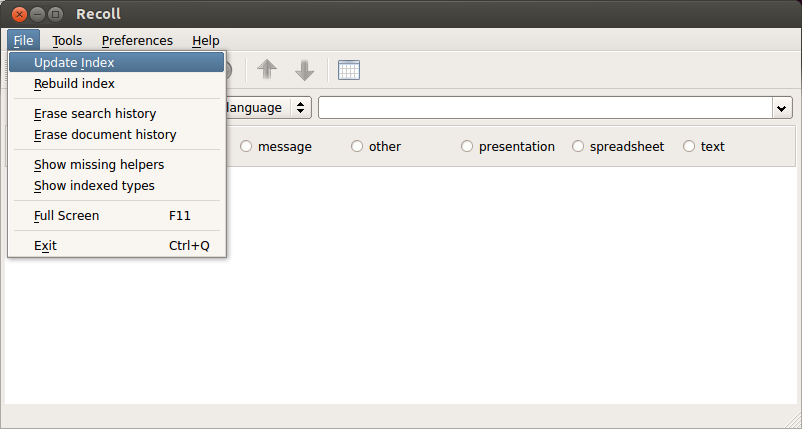
As documents are added, updated or removed, you will need to update an existing document index. You can do it manually by clicking on Update Index menu.
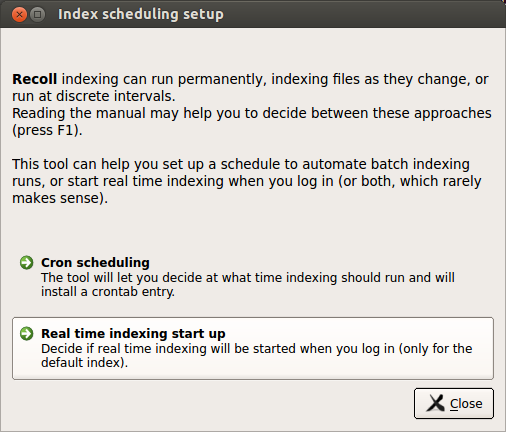
You can also update an existing document index automatically, either with a periodic cron job or with a background daemon process.
Support Xmodulo
This website is made possible by minimal ads and your gracious donation via PayPal or credit card
Please note that this article is published by Xmodulo.com under a Creative Commons Attribution-ShareAlike 3.0 Unported License. If you would like to use the whole or any part of this article, you need to cite this web page at Xmodulo.com as the original source.

Xmodulo © 2021 ‒ About ‒ Write for Us ‒ Feed ‒ Powered by DigitalOcean