How to deduplicate files on Linux with dupeGuru
Last updated on November 25, 2020 by Adrien Brochard
Recently, I was given the task to clean up my father's files and folders. What made it difficult was the abnormal amount of duplicate files with incorrect names. By keeping a backup on an external drive, simultaneously editing multiple versions of the same file, or even changing the directory structure, the same file can get copied many times, change names, change locations, and just clog disk space. Hunting down every single one of them can become a problem of gigantic proportions. Hopefully, there exists nice little software that can save your precious hours by finding and removing duplicate files on your system: dupeGuru. Written in Python, this file deduplication software switched to a GPLv3 license a few hours ago. So time to apply your new year's resolutions and clean up your stuff!
Install dupeGuru on Linux
On Ubuntu, you can add the Hardcoded Software PPA:
$ sudo apt-add-repository ppa:hsoft/ppa $ sudo apt-get update
And then install with:
$ sudo apt-get install dupeguru-se
On Arch Linux, the package is present in the AUR.
If you prefer compiling it yourself, the sources are on GitHub.
Basic Usage of dupeGuru
dupeGuru is conceived to be fast and safe. Which means that the program is not going to run berserk on your system. It has a very low risk of deleting stuff that you did not intend to delete. However, as we are still talking about file deletion, it is always a good idea to stay vigilant and cautious: a good backup is always necessary.
Once you took your precautions, you can launch dupeGuru via the command:
$ dupeguru_se
You should be greeted by the folder selection screen, where you can add folders to scan for deduplication.
Once you selected your directories and launched the scan, dupeGuru will show its results by grouping duplicate files together in a list.
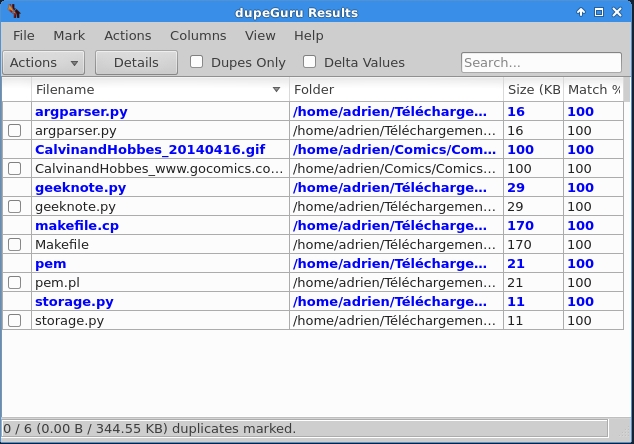
Note that by default dupeGuru matches files based on their content, and not their name. To be sure that you do not accidentally delete something important, the match column shows you the accuracy of the matching algorithm. From there, you can select the duplicate files that you want to take action on, and click on Actions button to see available actions.
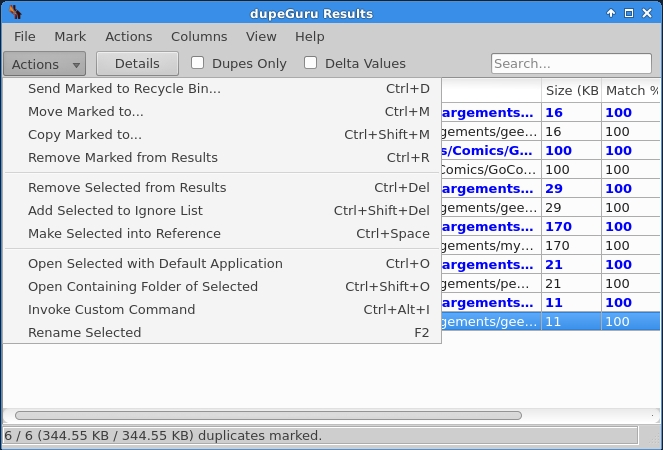
The choice of actions is quite extensive. In short, you can delete the duplicates, move them to another location, ignore them, open them, rename them, or even invoke a custom command on them. If you choose to delete a duplicate, you might get as pleasantly surprised as I was by available deletion options.
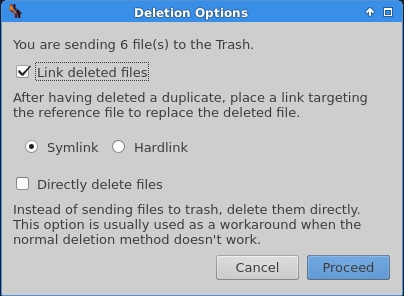
You can not only send the duplicate files to the trash or delete them permanently, but you can also choose to leave a link to the original file (either using a symlink or a hardlink). In oher words, the duplicates will be erased, and a link to the original will be left instead, saving a lot of disk space. This can be particularly useful if you imported those files into a workspace, or have dependencies based on them.
Another fancy option: you can export the results to a HTML or CSV file. Not really sure why you would do that, but I suppose that it can be useful if you prefer keeping track of duplicates rather than use any of dupeGuru's actions on them.
Finally, last but not least, the preferences menu will make all your dream about duplicate busting come true.
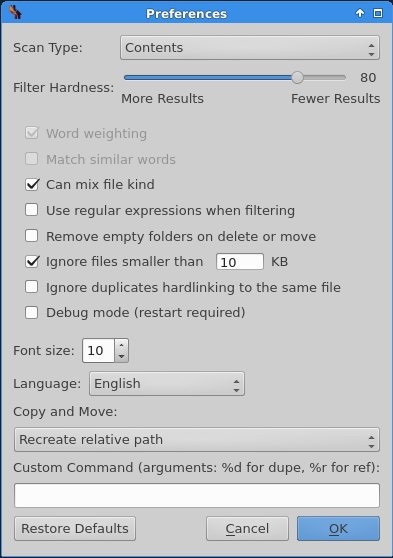
There you can select the criterion for the scan, either content based or name based, and a threshold for duplicates to control the number of results. It is also possible to define the custom command that you can select in the actions. Among the myriad of other little options, it is good to notice that by default, dupeGuru ignores files less than 10KB.
For more information, I suggest that you go check out the official website, which is filled with documention and other goodies.
To conclude, dupeGuru is my go-to software whenever I have to prepare a backup or to free some space. I find it powerful enough for advanced users, and yet intuitive to use for newcomers. Cherry on the cake: dupeGuru is cross platform, which means that you can also use it for your Mac or Windows PC. If you have specific needs, and want to clean up music or image files, there exists two variations: dupeguru-me and dupeguru-pe, which respectively find duplicate audio tracks and pictures. The main difference from the regular version is that it compares beyond file formats and takes into account specific media meta-data like quality and bit-rate.
What do you think of dupeGuru? Would you consider using it? Or do you have any alternative deduplication software to suggest? Let us know in the comments.
Support Xmodulo
This website is made possible by minimal ads and your gracious donation via PayPal or credit card
Please note that this article is published by Xmodulo.com under a Creative Commons Attribution-ShareAlike 3.0 Unported License. If you would like to use the whole or any part of this article, you need to cite this web page at Xmodulo.com as the original source.

Xmodulo © 2021 ‒ About ‒ Write for Us ‒ Feed ‒ Powered by DigitalOcean