How to replicate a MySQL database on Linux
Last updated on September 23, 2020 by Dan Nanni
Database replication is a technique where a given database is copied to one or more locations, so that the reliability, fault-tolerance or accessibility of the database can be improved. Replication can be snapshot-based (where entire data is simply copied over to another location), merge-based (where two or more databases are merged into one), or transaction-based (where data updates are periodically applied from master to slaves).
MySQL replication is considered as transactional replication. To implement MySQL replication, the master keeps a log of all database updates that have been performed. The slave(s) then connect to the master, read individual log entries, and perform recorded updates. Besides maintaining a transaction log, the master performs various housekeeping tasks, such as log rotation and access control. When new transactions occur and get logged on the master server, the slaves commit the same transactions on their copy of the master database, and update their position in the master server's transaction log. This master-to-slave replication process is done asynchronously, which means that the master server doesn't have to wait for the slaves to catch up. If the slaves are unable to connect to the master for a period of time, they will download and execute all pending transactions when connectivity is re-established.
Database replication allows one to have an exact copy of a live database of a master server at another remote server (slave server) without taking the master server offline. In case the master server is down or having any trouble, one can temporarily point database clients or DNS resolver to the slave server's IP address, achieving transparent failover. It is must be noted that MySQL replication is not a backup solution. For example, if an unintended DELETE command gets executed in the master server by accident, the same transaction will mess up all slave servers.
In this article, we will demonstrate master-slave based MySQL replication on two Linux computers. Let's assume that the IP addresses of master/slave servers are 192.168.2.1 and 192.168.2.2, respectively.
Setting up a Master MySQL Server
This part will explain the steps needed on the master server.
First, log in to MySQL, and create test_repl database.
$ mysql -u root -p
mysql> CREATE DATABASE test_repl;
Next, create a table inside test_repl database, and insert three sample records.
mysql> USE test_repl; mysql> CREATE TABLE employee (EmployeeID int, LastName varchar(255), FirstName varchar(255), Address varchar(255), City varchar(255)); mysql> INSERT INTO employee VALUES(1,"LastName1","FirstName1","Address1","City1"),(2,"Lastname2","FirstName2","Address2","City2"),(3,"LastName3","FirstName3","Address3","City4");
After exiting the MySQL server, edit my.cnf file using your favorite text editor. my.cnf is found under /etc, or /etc/mysql directory.
# nano /etc/my.cnf
Add the following lines under [mysqld] section.
[mysqld] server-id=1 log-bin=master-bin.log binlog-do-db=test_repl innodb_flush_log_at_trx_commit=1 sync_binlog=1
The server-id option assigns an integer ID (ranging from 1 to 2^23) to the master server. For simplicity, ID 1 and 2 are assigned to the master server and the slave server, respectively. The master server must enable binary logging (with log-bin option), which will activate the replication. Set the binlog-do-db option to the name of a database which will be replicated to the slave server. The innodb_flush_log_at_trx_commit=1 and sync_binlog=1 options must be enabled for the best possible durability and consistency in replication.
After saving the changes in my.cnf, restart mysqld daemon.
# systemctl restart mysqld
or:
# /etc/init.d/mysql restart
Log in to the master MySQL server, and create a new user for a slave server. Then grant replication privileges to the new user.
mysql> CREATE USER [email protected]; mysql> GRANT REPLICATION SLAVE ON *.* TO [email protected] IDENTIFY BY 'repl_user_password'; mysql> FLUSH PRIVILEGES;
A new user for the slave server is repl_user, and its password is repl_user_password. Note that the master MySQL server must enable remote access for a remote slave server which needs to log in to the master server as repl_user from external networks.
Finally, check the master server status by executing the following command on the server.
mysql> SHOW MASTER STATUS;

Please note that the first and second columns (e.g., master-bin.000002 and 107) will be used by the slave server to perform master-to-slave replication.
Setting up a Slave MySQL Server
Now it's time to set up the configuration of a slave MySQL server.
First, open my.cnf on a slave server using your favorite text editor, and add the following entries under [mysqld] section.
# nano /etc/my.cnf
server-id = 2 master-host = 192.168.2.1 master-connect-retry = 60 master-user = repl_user master-password = repluser master-info-file = mysql-master.info relay-log-index = /var/lib/mysql/slave-relay-bin.index relay-log-info-file = /var/lib/mysql/mysql-relay-log.info relay-log = /var/lib/mysql/slave-relay-bin log-error = /var/lib/mysql/mysql.err log-bin = /var/lib/mysql/slave-bin
Save the changes in my.cnf, and restart mysqld daemon.
# systemctl restart mysqld
or:
# /etc/init.d/mysql restart
Log in into the slave MySQL server, and type the following commands.
mysql> CHANGE MASTER TO MASTER_HOST='192.168.2.1', MASTER_USER='repl_user', MASTER_PASSWORD='repl_user_password', MASTER_LOG_FILE='master-bin.000002', MASTER_LOG_POS=107; mysql> SLAVE START; mysql> SHOW SLAVE STATUS G;
With the above commands, the local MySQL server becomes a slave server for the master server at 192.168.2.1. The slave server then connects to the master server as repl_user user, and monitors master-bin.000002 binary log file for replication.
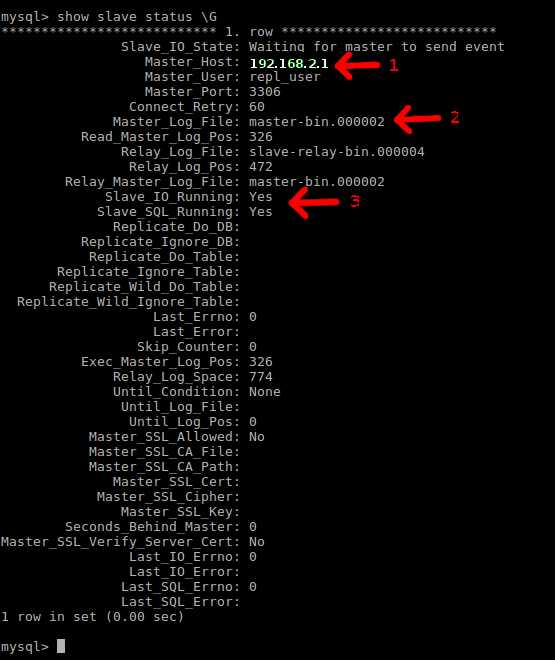
The above screenshot shows the status of the slave server. To find out whether replication is successful, take a note of three fields in the status output. First, the Master_Host field is supposed to show the IP address of the master server. Second, the Master_User field must display the user name created on the master server for replication. Finally, the Slave_IO_Running should display Yes.
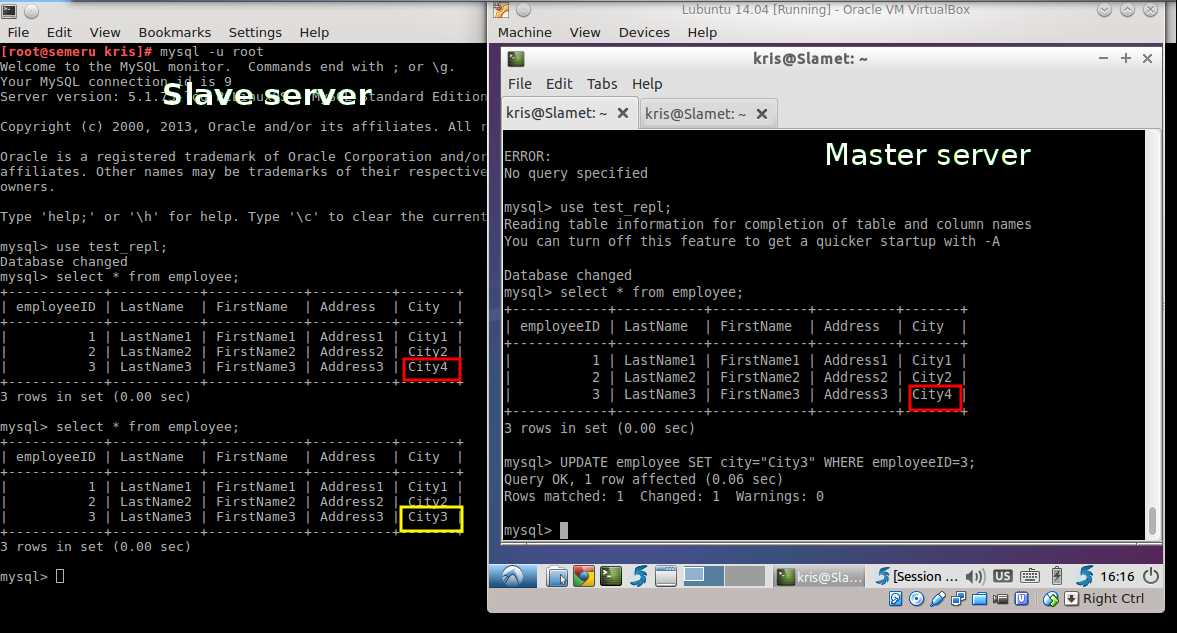
When the slave server starts working, it will automatically read the database log in the master server, and create the same table(s) and entries if they are not found in the slave. The screenshot below shows that the slave server has the same entries in the employee table as the master server (see the red square). When the city value is updated from the master server, the change is automatically replicated to the slave server (see the yellow square).
Support Xmodulo
This website is made possible by minimal ads and your gracious donation via PayPal or credit card
Please note that this article is published by Xmodulo.com under a Creative Commons Attribution-ShareAlike 3.0 Unported License. If you would like to use the whole or any part of this article, you need to cite this web page at Xmodulo.com as the original source.

Xmodulo © 2021 ‒ About ‒ Write for Us ‒ Feed ‒ Powered by DigitalOcean