How to set up RAID 10 for high performance and fault tolerant disk I/O on Linux
Last updated on August 27, 2020 by Gabriel Cánepa
A RAID 10 (aka RAID 1+0 or stripe of mirrors) array provides high performance and fault-tolerant disk I/O operations by combining features of RAID 0 (where read/write operations are performed in parallel across multiple drives) and RAID 1 (where data is written identically to two or more drives).
In this tutorial, I'll show you how to set up a software RAID 10 array using five identical 8 GiB disks. While the minimum number of disks for setting up a RAID 10 array is four (e.g., a striped set of two mirrors), we will add an extra spare drive should one of the main drives become faulty. We will also share some tools that you can later use to analyze the performance of your RAID array.
Please note that going through all the pros and cons of RAID 10 and other partitioning schemes (with different-sized drives and filesystems) is beyond the scope of this post.
How Does a Raid 10 Array Work?
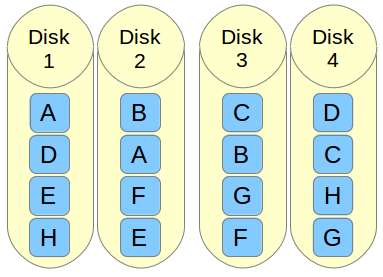
If you need to implement a storage solution that supports I/O-intensive operations (such as database, email, and web servers), RAID 10 is the way to go. Let me show you why. Let's refer to the below image.
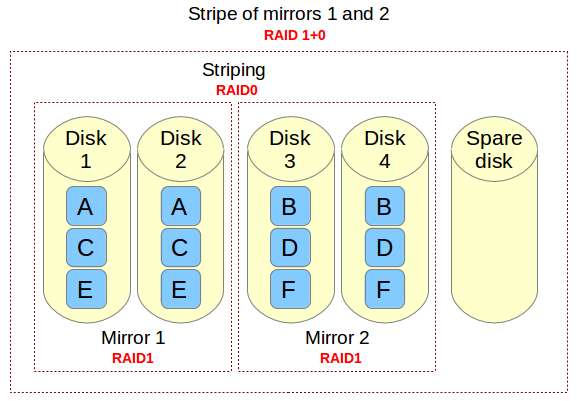
Imagine a file that is composed of blocks A, B, C, D, E, and F in the above diagram. Each RAID 1 mirror set (e.g., Mirror 1 or 2) replicates blocks on each of its two devices. Because of this configuration, write performance is reduced because every block has to be written twice, once for each disk, whereas read performance remains unchanged compared to reading from single disks. The bright side is that this setup provides redundancy in that unless more than one of the disks in each mirror fail, normal disk I/O operations can be maintained.
The RAID 0 stripe works by dividing data into blocks and writing block A to Mirror 1, block B to Mirror 2 (and so on) simultaneously, thereby improving the overall read and write performance. On the other hand, none of the mirrors contains the entire information for any piece of data committed to the main set. This means that if one of the mirrors fail, the entire RAID 0 component (and therefore the RAID 10 set) is rendered inoperable, with unrecoverable loss of data.
Setting up a RAID 10 Array
There are two possible setups for a RAID 10 array: complex (built in one step) or nested (built by creating two or more RAID 1 arrays, and then using them as component devices in a RAID 0). In this tutorial, we will cover the creation of a complex RAID 10 array due to the fact that it allows us to create an array using either an even or odd number of disks, and can be managed as a single RAID device, as opposed to the nested setup (which only permits an even number of drives, and must be managed as a nested device, dealing with RAID 1 and RAID 0 separately).
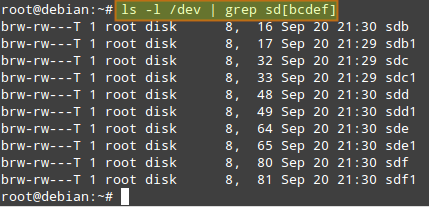
It is assumed that you have mdadm installed, and the daemon running on your system. Refer to this tutorial for details. It is also assumed that a primary partition sd[bcdef]1 has been created on each disk. Thus, the output of:
$ ls -l /dev | grep sd[bcdef]
should be like:
Let's go ahead and create a RAID 10 array with the following command:
# mdadm --create --verbose /dev/md0 --level=10 --raid-devices=4 /dev/sd[bcde]1 --spare-devices=1 /dev/sdf1

When the array has been created (it should not take more than a few minutes), the output of:
# mdadm --detail /dev/md0
should look like:
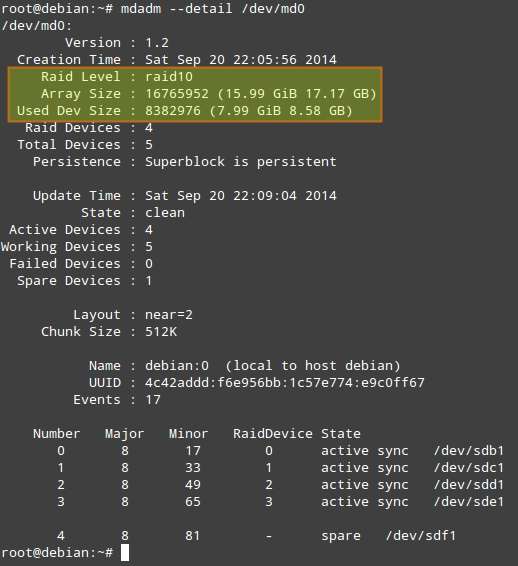
A couple of things to note before we proceed further.
1. "Used Dev Space" indicates the capacity of each member device used by the array.
2. "Array Size" is the total size of the array. For a RAID 10 array, this is equal to (N*C)/M, where N: number of active devices, C: capacity of active devices, M: number of devices in each mirror. So in this case, (N*C)/M equals to (4*8GiB)/2 = 16GiB.
3. "Layout" refers to the fine details of data layout. The possible layout values are as follows.
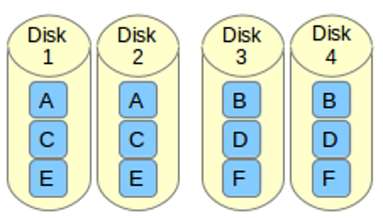
n (default option): means near copies. Multiple copies of one data block are at similar offsets in different devices. This layout yields similar read and write performance than that of a RAID 0 array.
o indicates offset copies. Rather than the chunks being duplicated within a stripe, whole stripes are duplicated, but are rotated by one device so duplicate blocks are on different devices. Thus subsequent copies of a block are in the next drive, one chunk further down. To use this layout for your RAID 10 array, add --layout=o2 to the command that is used to create the array.
f represents far copies (multiple copies with very different offsets). This layout provides better read performance but worse write performance. Thus, it is the best option for systems that will need to support far more reads than writes. To use this layout for your RAID 10 array, add --layout=f2 to the command that is used to create the array.
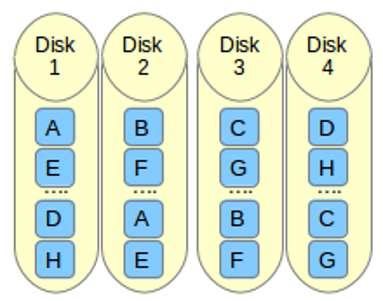
The number that follows the n, f, and o in the --layout option indicates the number of replicas of each data block that are required. The default value is 2, but it can be 2 to the number of devices in the array. By providing an adequate number of replicas, you can minimize I/O impact on individual drives.
4. Chunk Size, as per the Linux RAID wiki, is the smallest unit of data that can be written to the devices. The optimal chunk size depends on the rate of I/O operations and the size of the files involved. For large writes, you may see lower overhead by having fairly large chunks, whereas arrays that are primarily holding small files may benefit more from a smaller chunk size. To specify a certain chunk size for your RAID 10 array, add --chunk=desired_chunk_size to the command that is used to create the array.
Unfortunately, there is no one-size-fits-all formula to improve performance. Here are a few guidelines to consider.
- Filesystem: overall, XFS is said to be the best, while EXT4 remains a good choice.
- Optimal layout: far layout improves read performance, but worsens write performance.
- Number of replicas: more replicas minimize I/O impact, but increase costs as more disks will be needed.
- Hardware: SSDs are more likely to show increased performance (under the same context) than traditional (spinning) disks.
RAID Performance Tests using dd
The following benchmarking tests can be used to check on the performance of our RAID 10 array (/dev/md0).
1. Write operation
A single file of 256MB is written to the device:
# dd if=/dev/zero of=/dev/md0 bs=256M count=1 oflag=dsync
512 bytes are written 1000 times:
# dd if=/dev/zero of=/dev/md0 bs=512 count=1000 oflag=dsync
With dsync flag, dd bypasses filesystem cache, and performs synchronized write to a RAID array. This option is used to eliminate caching effect during RAID performance tests.
2. Read operation
256KiB*15000 (3.9 GB) are copied from the array to /dev/null:
# dd if=/dev/md0 of=/dev/null bs=256K count=15000
RAID Performance Tests Using Iozone
Iozone is a filesystem benchmark tool that allows us to measure a variety of disk I/O operations, including random read/write, sequential read/write, and re-read/re-write. It can export the results to a Microsoft Excel or LibreOffice Calc file.Installing Iozone on CentOS/RHEL 7
Enable Repoforge. Then:
# yum install iozone
Installing Iozone on Debian 7 or later
# aptitude install iozone3
The iozone command below will perform all tests in the RAID-10 array:
# iozone -Ra /dev/md0 -b /tmp/md0.xls
-R: generates an Excel-compatible report to standard out.-a: runsiozonein a full automatic mode with all tests and possible record/file sizes. Record sizes: 4k-16M and file sizes: 64k-512M.-b /tmp/md0.xls: stores test results in a specified file.
Hope this helps. Feel free to add your thoughts or add tips to consider on how to improve performance of RAID 10.
Support Xmodulo
This website is made possible by minimal ads and your gracious donation via PayPal or credit card
Please note that this article is published by Xmodulo.com under a Creative Commons Attribution-ShareAlike 3.0 Unported License. If you would like to use the whole or any part of this article, you need to cite this web page at Xmodulo.com as the original source.

Xmodulo © 2021 ‒ About ‒ Write for Us ‒ Feed ‒ Powered by DigitalOcean